BeautifulSoup 라이브러리란?
Requests로 받은 데이터를 BeautifulSoup객체화를 진행해주는 라이브러리
이게 왜 필요하냐?
제가 Requests를 통해서 받아온 데이터를 확인할려면 어떤 결과.text를 통해서 결과를 확이해봤습니다. 그 데이터를 잘 보시면 html 문서처럼 잘 받아왔다고 생각하실 수 있습니다. 하지만 실제로는 그 데이터 타입이 어떻게 생겼었냐면 문자의 맨 앞을 보시면 작은 따음표로 시작한 것을 알 수 있습니다. 그 작은 따음표 의미가 무엇이냐면 사람이 쓰고 있는 일반적인 텍스트(글자)라는 개념이였습니다. 자 그런데, 우리가 무엇을 할거였냐면 컴퓨터한테 그 내용을 해석시켜서 그 많은 요소들중에 내가 필요한 부분만 뽑아다줘라고 요청할거였어요. 그럴려면 그 정보를 컴퓨터가 알아먹을 수 있는 언어로 바꿔줘야합니다. 즉, HTML 언어로 바꿔줘야합니다. 내가 넘겨 받은 텍스트 정보를 컴퓨터가 알 수 있는 언어로 바꿔주는 라이브러리가 BeautifulSoup 라이브러리입니다.
오늘은 naver 사이트를 크롤링해줄 것입니다.



네이버에서 저렇게 메일 부분을 가져와줄 것입니다.

메일이라고 적혀있는 부분에다가 우클릭을하게 되면 검사라는 부분이 뜹니다. 검사를 클릭하게 되면 아래 사진처럼 a태그 부분이 나타나는 파란색으로 나타나는 것을 확인할 수 있습니다.

그래서 a태그 부분을 가져왔습니다.

그런데 저희는 메일이라고 적혀있는 a태그만 필요한데 그뿐만 아니라, 수도록 a태그를 가져왔습니다.
가져온 a태그가 너무 많은데 선택자를 통해서 특정한 a태그만 가져오도록해주셌습니다.
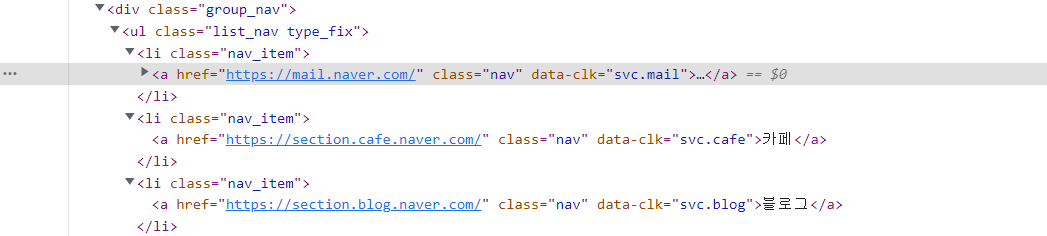
크롬 개발자 도구를 통해서 코드를 보면 메일, 카페 이런 글자부분들이 nav라는 class 선택자에 해당하는 것을 확인할 수 있습니다. 그래서 nav 부분을 크롤링해달라고 설정해줬습니다.
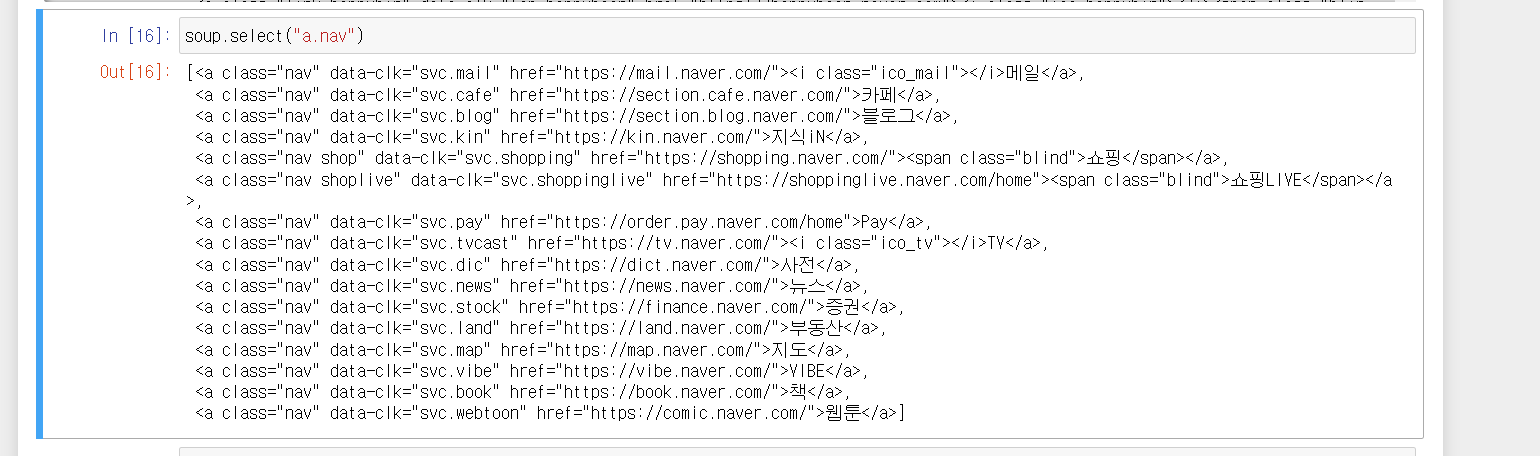
그러니 nav 부분을 다 가져온 것을 확인할 수 있습니다. 요번에는 그중에 메일 부분만 가져오게 해줄 것입니다.

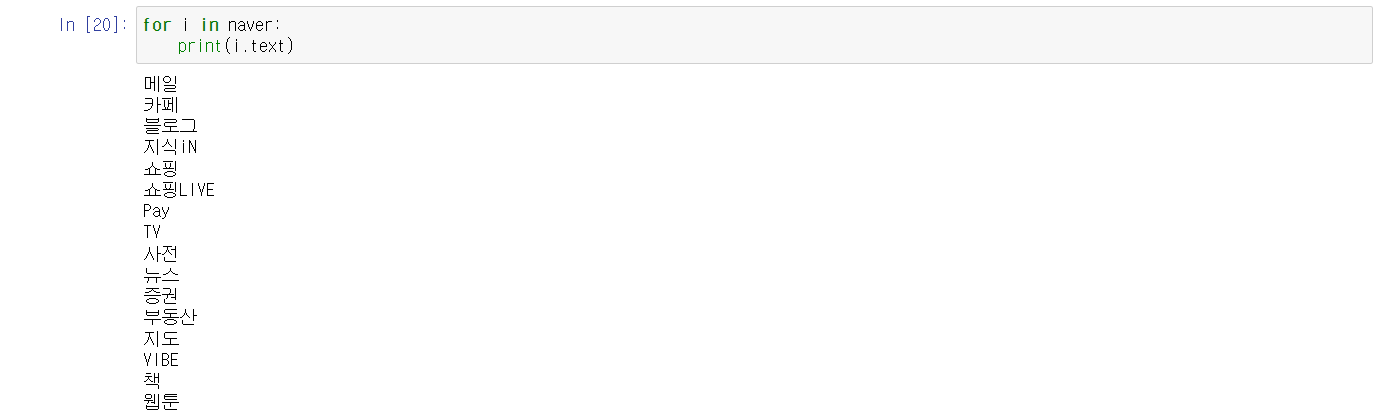
그런데 아직 크롤링이 안 끝났습니다. 아직은 가져온 정보가 사용자를 위한 정보가 아니고 컴퓨터를 위한 정보입니다. 왜냐하면 저는 순수히 오직 글자 정보가 필요한데 html 형태로 글이 나타나있기 때문입니다. 요번에는 사용자를 위한 정보로 가져오기 위해서 html 형태에서 텍스트 형태로 바꿔서 정보를 가져와줄 것입니다.

그런데 만약 한개를 크롤링하는게 아니고 여러개 크롤링할 때 저희가 지금 가져오는 방법대로 가져오면 시간이 엄청나게 오래 걸릴 것입니다. 그래서 그럴 때는 반복문을 사용해서 가져오시면 됩니다.
'파이썬' 카테고리의 다른 글
| 파이썬 업무 자동화 - 엑셀의 구성 요소 (0) | 2022.09.27 |
|---|---|
| 파이썬 증권 데이터 수집과 분석으로 신호와 소음 찾기1 (0) | 2022.05.18 |
| 파이썬을 활용한 크롤링(Melon 홈페이지 정보 가지고 오기 실습) (0) | 2022.05.08 |
| 파이썬을 활용한 크롤링(크롤링 개요/Request 사용법3) (0) | 2022.05.08 |
| 파이썬을 활용한 크롤링(크롤링 개요/Request 사용법2) (0) | 2022.05.08 |