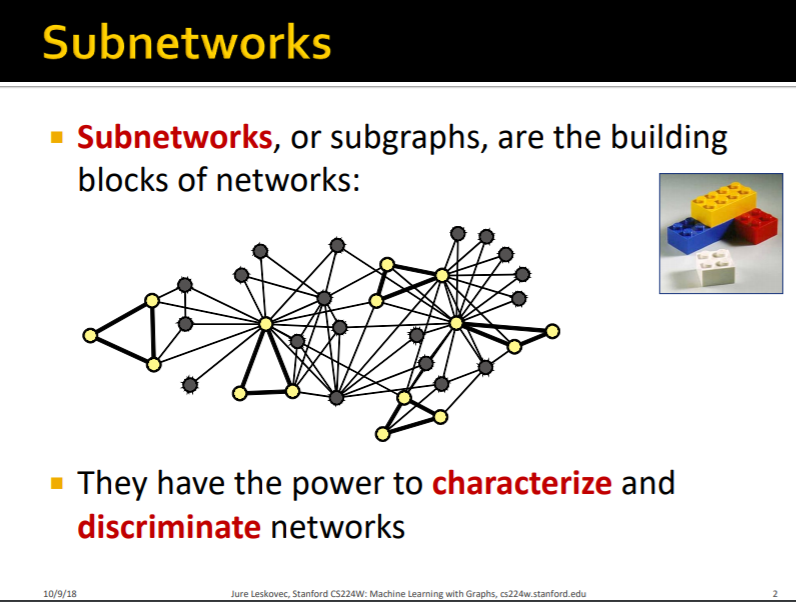
small building blocks가 모여서 big network를 구성합니다. 그리고 supgraph를 통해서 network를 characterize하고 discriminate 할 수 있습니다. 그리고 레스코백 교수는 이걸 레고로 비유를 하였습니다. 레고 큐브 하나하나가 subgraph가 되고, 레고로 만든 결과물이 network가 됩니다.

이 사진을 보고 아까전에 말했듯이 building vlocks가 subgraph가 되고 subgraph가 big networks가 되는 것을 알 수 있습니다.

노드가 3개인 비동형 subgraph(directed)는 위와 같은 경우의 수를 가집니다. 그리고 각 경우의 수중에 모양의 subgraph는 없습니다.

그렇다면 이렇게 bignetwork를 구성하는 subgraph들의 frequency와 occurence에 따라 정해지는 significant(중요성)에 대한 metric에 대해 생각해볼 수 있습니다. The significance value가 negative 혹은 positive하다면 netowk내에서 under-represented 되거나 over-represented라고 해석할 수 있습니다. 그렇게 되면 우리는 주어진 network에서 가능한 graph에 대한 significance profile을 작성할 수 있습니다.

그리고 이렇게 만든 서로 다른 네트워크의 프로필을 비교합니다.

각 네트워크 위의 subgraph들이 얼마나 있는지 확인할 수 있다.

network motif를 정의하자면 significant, recurring, pattern interconnections in the network입니다.
Network motif를 정의하기 위해서는 pattern, recurring, significant의 대한 개념을 정의해야합니다.

Pattern은 subgraph가 유도되는지
Reccuring은 몇번, 빈도수가 얼마인지
Significant는 예상보다 얼마나 나타는지

Motif는 네트워크 작동의 이해를 돕고 주어진 상황에서 네트워크의 작동과 이해를 돕고 주어진 상황에서 네트워크의 작동과 대응을 에측할 수 있도록 도와준다.
교수가 이런 Motif의 예시들을 3개 나열하였다. 세개의 예시들이 있다.
- Feed-forward loopps : skip connection과 동일합니다

- Parallel loops : 먹이사슬

Single-input modules : 유전자 네트워크
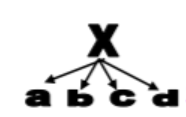


위와 같은 supgraph를 오른쪽 네트워크에서 찾을 수 있는지 알아볼 수 있습니다.

recurrence의 개념을 정의하는 것입니다. recurrence의 개념은 중복을 허용하여 주어진 motif의 패턴이 몇번 발견되는지 아는 것입니다. 위와 같이 어떠한 motif가 주어졌을 때, 다음과 같은 graph에서는 해당 motif가 4번 발견됩니다. node의 중복을 허용하기는 하지만 결과적으로 발견된 4개의 motif는 다르다고 할 수 있습니다.

이러한 motif가 {1,2,3,4,5} 이렇게 4번이 활용 된다는 것을 알 수 있습니다.
{1,2,3,4,6}
{1,2,3,4,7}
{1,2,3,4,8}

다음으로는 significance를 계산하는 과정을 가집니다. Significance를 계산하는 핵심 아이디어는 비교하고자하는 network와 랜덤 생성된 network에서 주어진 motif의 발생 빈도를 비교하는 것입니다.

이 motif가 random netowrk보다 real network에서 훨씬 고빈도로 나타나게됩니다.

이 슬라이드에서는 significance를 구하는 식을 알려준다. 식은 실제 네트워크에서 발생한 쇳수에서 랜덤 네트워크에서 평균 발행 횟수를 뺀후 표준편차로 나눠주는 것입니다. 이러한 값은 네트워크가 커질수록 더 커집니다.
이제 configuration model을 설명할 차례인데 일단 이 파트에서는 real network와 비교할 random graph가 필요하기 때문에, 차수가 주어질 때 랜덤 그래프를 생성하는 방법으로 두가지를 소개합니다.
첫번째 방법은 spoke를 이용한 방법이고 두번째는, switching을 이요한 방법입니다.
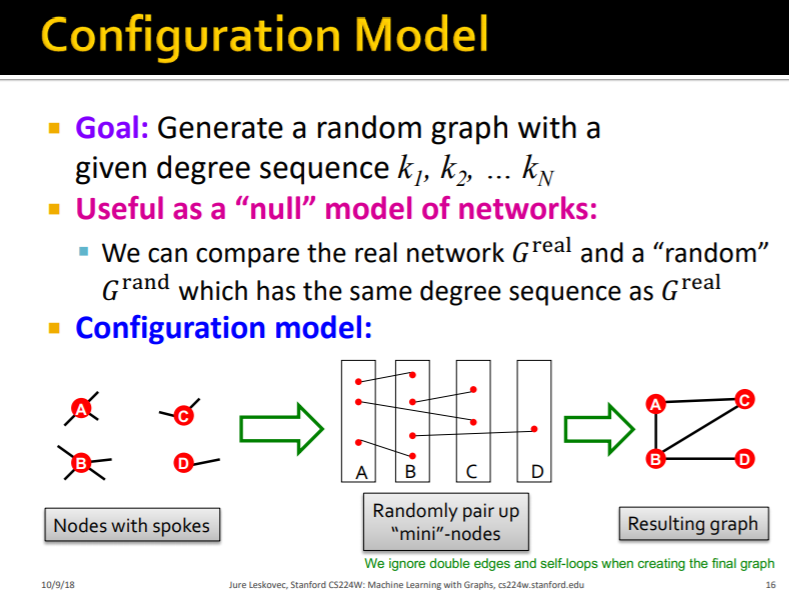
- 먼저 spoke가 있는 노드들을 준비합니다.(방향성 있는 spoke도 가능)
- 노드를 하나의 파티션으로 생각하고, spoke끼리 연결을합니다.
- 두번째 그림처럼 연결된 노드쌍들을 그래프로 만들면 랜덤 그래프를 얻을 수 있습니다.
장점 : 이 방법은 굉장히 빠르고 효율적이다.
단점 : NodeB의 경우에서 Double Edge나 Self-Loops는 고려하지 못해서 기존의 주어진 degree를 유지하지 못하는 단점이 있습니다.
이러한 단점을 가진 spoke 방법을 보완한게 switching 방법입니다.

- switching은 edge들의의 쌍을 선택해서 랜덤으로 exchange하는 방법입니다.
장점 : spoke 방법에서는 degree sequence를 잃었는데 이 방법에서는 degree sequence를 지킬 수 있게 됩니다.
단점 : spoke보다 expensive한 방법이고 rewiring 과정이 매우 느립니다.
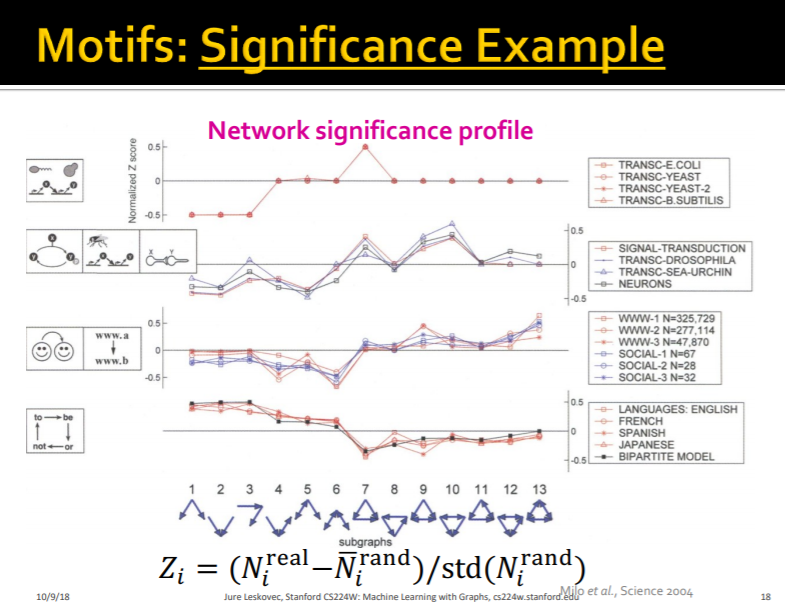
이 사진은 significance 구한 것의 example입니다.

위에서 설명한 내용을 다시 요약한 부분인데요. Z-score를 통하여 network motif에서의 중요 subgraph들을 pick합니다.
그리고 일반적으로 10,000~100,000개의 random subraph를 만든다고합니다.

이렇게 motif에도 다양한 번형들이 있는 것을 볼 수 있습니다.

이 슬라이드에서는 전에 있던 슬라이들에서 있었던 것들을 복습해주는 부분인데요.
- 뉴럴 네트워크와 유전자 네트워크는 유사한 모티프를 포함합니다.
- 둘다 sensory(감각적이고) and acting component(행동구성)를 가진 정보처리 네트워크입니다.
- parallel loops는 먹이사슬을 가지고 있습니다.
- www network는 양방향성 링크를 가지고 있습니다.

Graphlets : 연결된 비동형 서브 그래프입니다.
isomorphic(동형) : 돌리면 똑같은 그래프가 되는 것
non-isomorphic(비동형) : 본격적으로 다른 그래프
간단하게 설명하자면
motif : 전체 네트워크 특징화
graphlet : 주어진 노드 특징화
위 사진을 보면 노드의 개수에 따른 그래프들을 보여줍니다. 그리고 저거 개수만큼이 그래프의 종류 수입니다.

-우리는 Graphlet을 통해 node-level subraph metric을 얻을 수 있습니다.
- 우리는 이 개념을 graphlets에 일반화 할 수 있습니다.
- GDV는 node가 touch하는 graphlets가 얼만큼 있는지 셉니다.

여기는 그래프의 자동형태를 알려줍니다.
automorphism orbit : 서브 그래프의 대칭을 고려합니다.
GDV : 각 orbit position에서 node의 빈도에 대한 벡터를 알려줍니다.
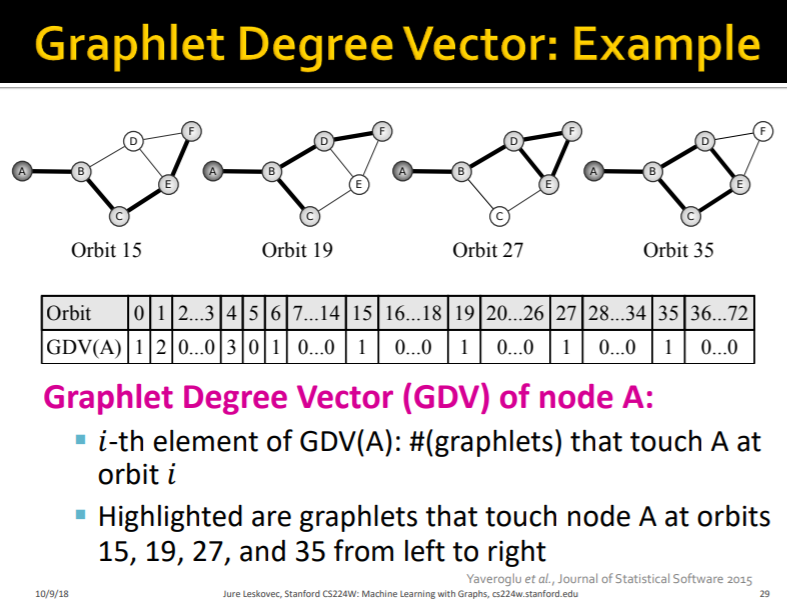
여기 graphlet 그림에서 graphlet이 0 ~ 72여서 GDV는 하나의 노드를 기준으로 73개의 차원으로 구성된 벡터임을 알 수 있습니다. 그리고 이 벡터를 가지고 노드를 특징화 할 수 있으며 다양하게 활용할 수 있습니다.

motif와 graphlet을 발견하기 위해서는 두가지 challenges가 필요합니다.
1. Enumerating : K-size의 가능한 모든 subgraph를 찾는 과정
2. Counting : 찾은 모든 subgraphs의 occurences를 세는 과정
하지만 이 과정에서 매우 복잡한 computational problem인 np-complete 문제가 발생하게 됩니다. 보통 motifs와 graphlets가 5개에서 8개의 노드로 구성되면서 combinatorial explosion이 발생하기 때문.

네트워크-중심 접근방식이 두가지가 있다. 앞서 설명한 방식들인 enumberating이랑 counting이 있다.
이거에 알고리즘들이 3종류를 알려줬다.
- Exact subgraph enumeration(ESU)
- Kavosh
- Subgraph sampling
이 위 3가지 알고리즘중에서 레스코벡 교수는 ESU 알고리즘을 소개하게 됩니다.

두가지 집합이 있다.
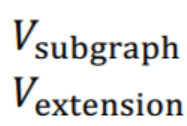
특정 시점까지 만들어놓은 부분그래프
그 subgraph를 확장하는데에 사용할 노드 후보군들의 집합
ESU 알고리즘은 v노드를 시작으로 새로운 노드를 추가해나가면서 subgraph를 만들어나가는 과정을 거칩니다. ESU 알고리즘은 v노드를 시작으로 새로운 노드를 추가해나가면서 subgraph를 만들어어나가는 과정을 거칩니다. ESU 알고리즘은 재귀적 구조를 가지고 있으면 현재 시점의 subgraph를 저장하는 Vsubgraph와 motif를 확장하기 위한 후보 노드를 보관하고 있는 Vextension로 구성하고 있습니다.

위 사진은 ESU 알고리즘의 수도코드입니다.

그리고 각 subgraph의 개수를 세보면 위와 같이 알수가 있습니다.

다음 단계는 counting 과정입니다. Count를 하는 기준은 non-isomorphic한 graph를 토대로 subgraph의 개수를 세주는 것입니다. 즉, 3개의 노드와 2개의 edge로 구성되어 있는 subgraph는 topologically equivalent한 isomorphic한 graph이기 때문에 해당 구조가 총 5번 나왔다고 할 수 있으며, 이 때 isomorphic을 구별하기 위해 Mckay의 naugty 알고리즘을 사용합니다.

bijection f:V(G) -> V(H)가 존재하면 그래프 G와 H는 isomorphic이다.
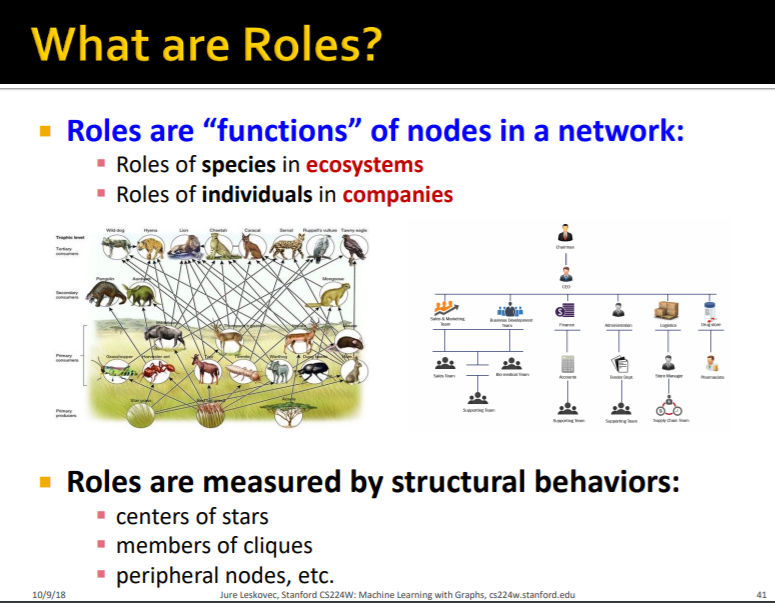
Roles이란 graph에서 노드의 function입니다. 네트워크에서 비슷한 위치, 기능을 하는 노드의 집합을 의미하는 자료구조입니다.
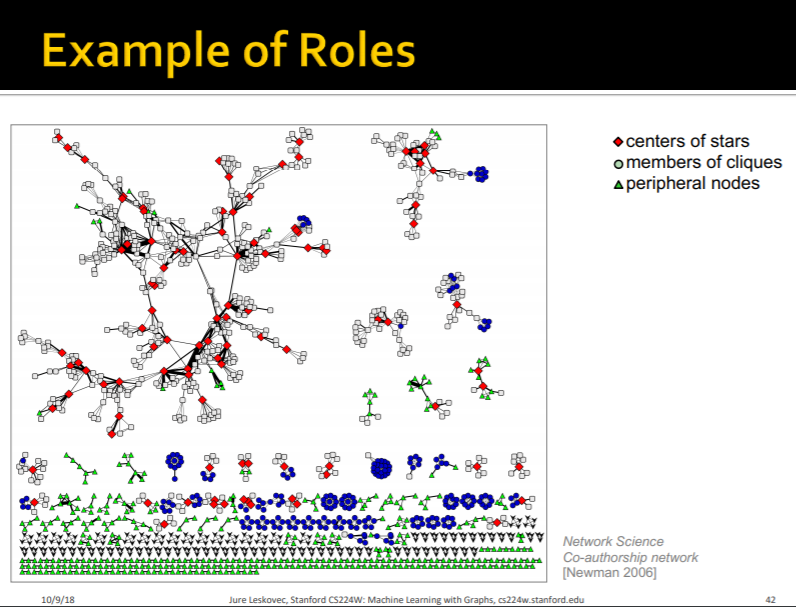
위 사진은 네트워크 상에서 노드들의 역할을 나타내는 사진입니다.

Role : 네트워크에 존재하는 비슷한 위치 및 기능을 가지는 nodes의 집합을 의미하는 자료구조입니다.

일단 위에 페이지까지 포함해서 43, 44페이지에서는 Roles와 Commnuities/Groups의 차이를 보여주고 있는데요. Role은 네트워크에서 유사한 역할을 하는 노드들의 집합이고 community는 네트워크에서 잘 연결되어 있는 group입니다.

그리고 이 사진은 Roles와 Commnuities의
차이점을 보여주는 사진입니다.

노드 u와 노드 v가 다른 노드들 사이의 관계가 동등하다면 ui와 v는 structural equivalence이다.

사진을 보면 u와 v가 structrual equivalence임을 알 수 있다.
structural equivalence : 노드 u와 v가 다른 노드와의 관계가 동일하다면 구조적으로 불 수 있다.

해당 예시 그래프에서 노드 3, 4가 structural equivalence임을 알 수 있습니다. 노드 간 structural equivalence를 찾을 때에는 어느 정도의 noise를 감안하기도합니다. 위의 예시를 보면 u,v 노드 아래의 3, 4 노드는 structurally equivalent하다고 한다. 다른 노드에 대한 관계가 동일하다는 것을 알 수 있습니다.

Roles는 네트워크 구조에 존재하는 노드의 서로 다른 특징을 구별하기 때문에 매우 중요합니다. 또한 노드의 Roles를 가지고 위와 같은 여러 과제를 수행할 수 있습니다.
Role에 대한 task 6가지로 분류
Role query : 알려진 target값과 비슷한 행동을하는 individual 식별
Role outliers : 비정상적인 행동을하는 individual 식별
Role dynamics : 비정상적인 행동변화 식별
Identity resolution : 새로운 네트워크에서 식별
Role transfer : 한 네트워크에 대한 지식 사용해서 다른 네트워크에 대한 예측
Network comparison : 네트워크 유사성 계산, 지식 전달을 위한 호환성 결정

RolX : Network에서 노드들의 Structural Roles를 발견하는 automatic한 방법입니다.
Rolx의 특징
- 비지도 학습
- 사전 정보 요구 X
- 각 노드에 role들의 mixed-membership 할당
- edge수에 따라서 선형적으로 크기가 커짐
Rolx에서 node role를 추출하는 과정

1. Node x Node 인접행렬 구하기
2. Recursive Feature Extraction을 통해서 Node x Feature행렬로 만들기
3. Role Extraction을 통해서 (Node x Role행렬), (Role x Feature)행렬을 나오게 한다.

네트워크 연결성으로 구조적 feature를 만드는 것을 보여주는 사진입니다.

기본 아이디어 : 노드의 기능을 집계해서 새로운 recursive feature를 생성하는 것입니다.
노드의 기본적인 이웃 feature 두가지
- Local features :
- 방향 그래프라면, in-and out-degree, total degree를 포함합니다.
- 가중 그래프라면, weighted feature versions를 포함합니다.
- Egonet features : 노드의 egonet에서 계산된 값
Egonet은 노드에서 유도된 subgraph의 노드와 이웃 그리고 모두 edges를 포함합니다.

Recursive는 이전에 나온 feature를 가지고 새로운 feature를 만드는 것입니다. 위에서는 이웃 노드들 간에 중간값을 가지고 새로운 feature를 만들었다고 예시에 나옵니다. 하지만 이렇게 하면 exponentially, 즉 매우 많은 feature가 나오게 되므로 pruning techique으로 제어합니다.

노드의 라벨(진보, 보수, 중립)이 주어지지 않았는데 알고리즘으로 어떤 노드가 central이고 peripheral인지 role을 구분했습니다. 맨 처음 role에 대해 설명했던대로 각 클러스터에 비슷한 role을 가진 노드들이 분포하는 것을 볼 수 있습니다.
'인공지능' 카테고리의 다른 글
| 밑바닥부터 시작하는 딥러닝1: Chapter 2 (0) | 2021.11.03 |
|---|---|
| 밑바닥부터 시작하는 딥러닝1: Chapter 1 (0) | 2021.11.03 |
| 인공지능과 미래 사회 공부 (1) | 2021.10.27 |
| 시계열 분석 프로그램 (0) | 2021.10.25 |
| CS224W 2021 Node Embeddings (0) | 2021.04.04 |